
Simple Process Mining Use Case
Root Cause Analysis on Disputes During Purchasing Business Process
Dataset source: Disco-Demo-Logs
In this portfolio, an use case on Process Mining (PM) is demonstrated. Process mining is a subset of the data mining field that bridge the fields of data science and process management to support the analysis of operational processes based on event data (e.g. event logs). The goal of process mining is to turn event data into insights and actions. The events found in event data typically refer to activities executed by resources at particular times and for particular cases. Event data are collected everywhere: in logistics, manufacturing, finance, healthcare, e-learning, egovernment, and many other domains. Therefore, process mining can also be applied in almost every domains. Several industries, in particular, have applied process mining extensively: Energy & Materials (e.g., oil & gas); Industrials (e.g., construction & engineering); Consumer Goods (e.g., food, automobiles & parts, personal products); Consumers Services (e.g., media, leisure, education); Healthcare (e.g., healthcare providers, medical research); Utilities (e.g., telecommunications, electricity); Financial (e.g., banking); and Technology (e.g., software and services). The application of process mining in those industries are well-compiled in the literature review by Zerbino et al.
Process mining provides the means to discover the model of real processes based on the actual event data, detect deviations of real processes compared to its standard operating procedures/business as usual state, analyze bottlenecks of the real processes, calculate waste from such bottleneck events, etc (Wil, 2018). However, process mining tends to be backward-looking, meaning that process mining alone shouldn’t be used to explore the impact of different process design alternatives or different scenarios. To explore them, it is better to utilize simulation, especially Discrete Event Simulation (DES), based on the model of real processes that has been discovered by process mining.
Many software programs have been created for process mining. Some require paid license (e.g. Disco by Fluxicon) while some are open-source (e.g., PM4Py by Fraunhofer Institute for Applied Information Technology and ProM By Process Mining Group and TU/e). For more flexibility on showcasing the use case, the open-source Python library PM4Py is used as the main process mining software.
Methodology
To emphasize the showcase of PM algorithms on this use case, the PM methodology, referred as PM2 (van Eck, M.L et al, 2015) is used.
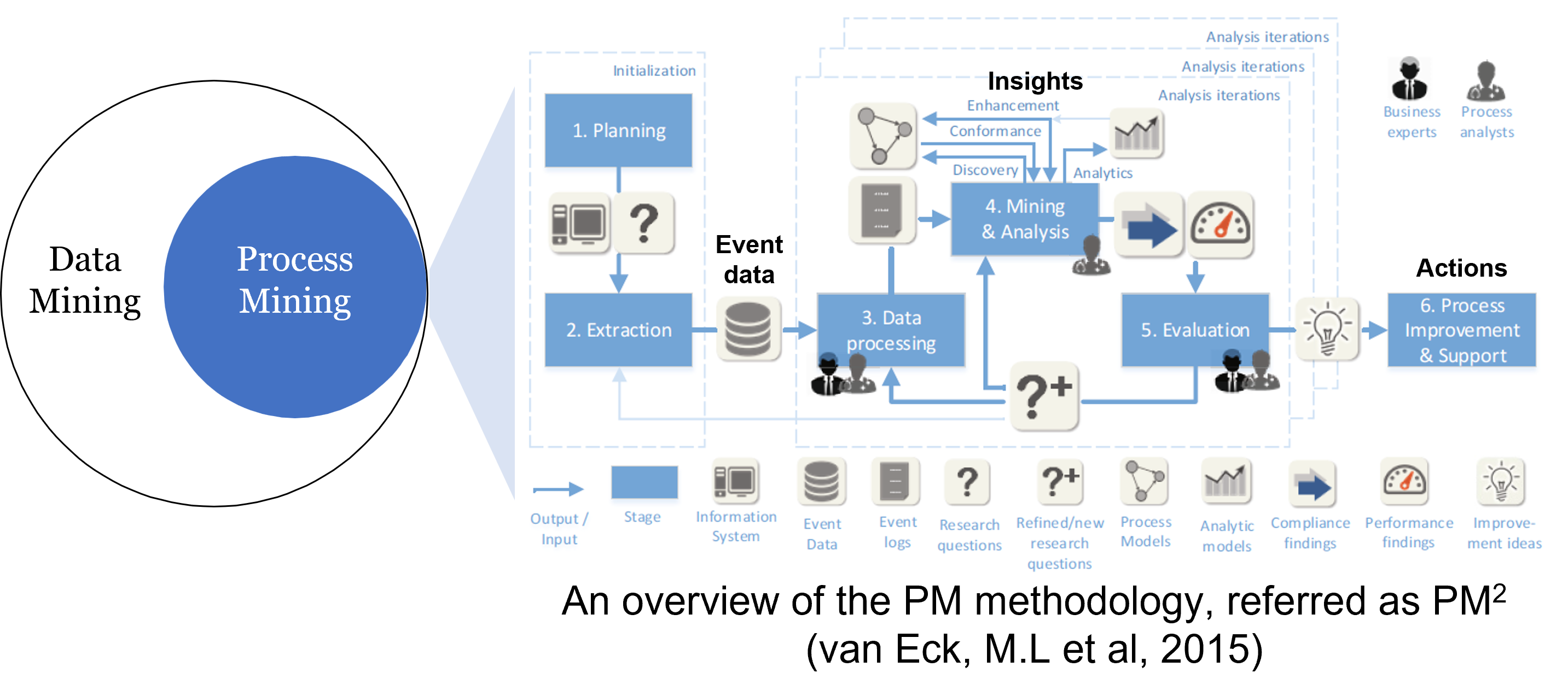
As a subset of the data mining field, PM’s methodology have some similarities with CRISP-DM (CRoss Industry Standard Process for Data Mining).
1. Data Extraction
In process mining, the data that is generally used is an event log where each event in the log is part of a case, represents an activity in a specific duration or point in time. Therefore, an event log can be seen as a collection of cases and many cases may have the same trace/sequence of events.
Source: http://www.processmining.org/event-data.html
# from CSV or Excel
import pandas as pd
raw_df = pd.read_csv(r"C:\Users\Torivor\Documents\Learning activities\Projects\Datasets for practice\Process mining examples\Disco-Demo-Logs\Demo Logs\PurchasingExample.csv")
raw_df.head(5)
| Case ID | Start Timestamp | Complete Timestamp | Activity | Resource | Role | |
|---|---|---|---|---|---|---|
| 0 | 339 | 2011/02/16 14:31:00.000 | 2011/02/16 15:23:00.000 | Create Purchase Requisition | Nico Ojenbeer | Requester |
| 1 | 339 | 2011/02/17 09:34:00.000 | 2011/02/17 09:40:00.000 | Analyze Purchase Requisition | Maris Freeman | Requester Manager |
| 2 | 339 | 2011/02/17 21:29:00.000 | 2011/02/17 21:52:00.000 | Amend Purchase Requisition | Elvira Lores | Requester |
| 3 | 339 | 2011/02/18 17:24:00.000 | 2011/02/18 17:30:00.000 | Analyze Purchase Requisition | Heinz Gutschmidt | Requester Manager |
| 4 | 339 | 2011/02/18 17:36:00.000 | 2011/02/18 17:38:00.000 | Create Request for Quotation Requester Manager | Francis Odell | Requester Manager |
Converting from event data to event log format
import pm4py
# format the raw dataframe with pm4py attributes to ensure accurate interpretation of the dataframe by pm4py modules.
formatted_df = pm4py.format_dataframe(raw_df, case_id='Case ID', activity_key='Activity', start_timestamp_key='Start Timestamp', timestamp_key = 'Complete Timestamp')
# convert the formatted dataframe into an event log, ensure that the dataframe has been
## formatted with pm4py attributes to ensure accurate interpretation of the dataframe by pm4py modules.
raw_event_log = pm4py.convert_to_event_log(formatted_df)
display(raw_event_log)
[{'attributes': {'concept:name': '1'}, 'events': [{'Case ID': 1, 'Start Timestamp': Timestamp('2011-01-01 00:00:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-01-01 00:37:00+0000', tz='UTC'), 'Activity': 'Create Purchase Requisition', 'Resource': 'Kim Passa', 'Role': 'Requester', 'concept:name': 'Create Purchase Requisition', 'time:timestamp': Timestamp('2011-01-01 00:37:00+0000', tz='UTC'), '@@index': 0, 'start_timestamp': Timestamp('2011-01-01 00:00:00+0000', tz='UTC')}, '..', {'Case ID': 1, 'Start Timestamp': Timestamp('2011-01-04 15:22:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-01-04 15:31:00+0000', tz='UTC'), 'Activity': 'Pay invoice', 'Resource': 'Pedro Alvares', 'Role': 'Financial Manager', 'concept:name': 'Pay invoice', 'time:timestamp': Timestamp('2011-01-04 15:31:00+0000', tz='UTC'), '@@index': 16, 'start_timestamp': Timestamp('2011-01-04 15:22:00+0000', tz='UTC')}]}, '....', {'attributes': {'concept:name': '997'}, 'events': [{'Case ID': 997, 'Start Timestamp': Timestamp('2011-05-25 04:20:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-05-25 05:04:00+0000', tz='UTC'), 'Activity': 'Create Purchase Requisition', 'Resource': 'Kim Passa', 'Role': 'Requester', 'concept:name': 'Create Purchase Requisition', 'time:timestamp': Timestamp('2011-05-25 05:04:00+0000', tz='UTC'), '@@index': 9115, 'start_timestamp': Timestamp('2011-05-25 04:20:00+0000', tz='UTC')}, '..', {'Case ID': 997, 'Start Timestamp': Timestamp('2011-05-29 10:18:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-05-29 10:44:00+0000', tz='UTC'), 'Activity': 'Analyze Request for Quotation', 'Resource': 'Magdalena Predutta', 'Role': 'Purchasing Agent', 'concept:name': 'Analyze Request for Quotation', 'time:timestamp': Timestamp('2011-05-29 10:44:00+0000', tz='UTC'), '@@index': 9118, 'start_timestamp': Timestamp('2011-05-29 10:18:00+0000', tz='UTC')}]}]
2. Data Preprocessing and Processing
Data preprocessing
Raw event log preprocessing
The raw event log can be refined to be more informational by calculating some useful features such as the *cycle time and lead time if the event log is an interval log (has a start and end timestamp).
*Cycle time definition: time or duration it takes to complete a given activity or task.
*Lead time definition: time it takes to complete the whole process, from the moment an order is created until the arrival/delivery of the product/service.
from pm4py.objects.log.util import interval_lifecycle
from pm4py.util import constants
'''
To store the calculated cycle time and lead time, PM4PY assigns the values to the following attributes =
@@approx_bh_partial_cycle_time: Incremental cycle time associated to the event (the cycle time of the last event is the cycle time of the instance)
@@approx_bh_partial_lead_time: Incremental lead time associated to the event
@@approx_bh_overall_wasted_time: Difference between the partial lead time and the partial cycle time values
@@approx_bh_this_wasted_time: Wasted time ONLY with regards to the activity described by the ‘interval’ event
@@approx_bh_ratio_cycle_lead_time: Measures the incremental Flow Rate (between 0 and 1).
'''
refined_event_log = interval_lifecycle.assign_lead_cycle_time(raw_event_log, parameters={
constants.PARAMETER_CONSTANT_START_TIMESTAMP_KEY: "start_timestamp",
constants.PARAMETER_CONSTANT_TIMESTAMP_KEY: "time:timestamp"})
Now, lets get a quick bird’s-eye view of the process. This can be done by visualizing the Petri Net of the process. To produce a Petri Net, first make a Heuristics Net of the process using the Heuristics Miner. Heuristics Miner is an algorithm that acts on the Directly-Follows Graph, providing way to handle with noise and to find common constructs (dependency between two activities, AND). The output of the Heuristics Miner is an Heuristics Net, an object that contains the activities and the relationships between said activities.
After producing the Heuristics Net, it can then be then converted into a Petri net. Petri nets are one of the most common formalism to express a process model. A Petri net is a directed bipartite graph, in which the nodes represent transitions and places. Arcs are connecting places to transitions and transitions to places, and have an associated weight. In other words, the Petri Net symbols are “places” (circles) that represent system states (e.g. activities) and “transitions” (rectangles) that represent the process proceeding on taking further actions without any additional system states (hence its denoted by its 0s performance metric), both connected by arrows known as “arcs.”
import pm4py
# producing the Heuristics Net from an event log, then convert into a Petri net.
net, initial_marking, final_marking = pm4py.discover_petri_net_heuristics(refined_event_log)
pm4py.write_pnml(petri_net=net, initial_marking=initial_marking, final_marking=final_marking, file_path="raw_petri_net.pnml")
from pm4py.visualization.petri_net import visualizer as pn_visualizer
parameters = {pn_visualizer.Variants.PERFORMANCE.value.Parameters.FORMAT: "png"}
'''
pn_visualizer.Variants.PERFORMANCE: This indicates that the model should be decorated according to performance (aggregated by mean) information obtained by applying replay.
'''
gviz_PERFORMANCE = pn_visualizer.apply(net, initial_marking, final_marking, parameters=parameters, variant=pn_visualizer.Variants.PERFORMANCE, log=refined_event_log)
# display the petri net decorated with the specified variant
pn_visualizer.view(gviz_PERFORMANCE)
replaying log with TBR, completed variants :: 0%| | 0/98 [00:00<?, ?it/s]

Conclusion:
Several disputes happened during the process which forced the process to loop awhile before continuing forward.
'''
pn_visualizer.Variants.FREQUENCY: This indicates that the model should be decorated according to frequency information obtained by applying replay.
'''
gviz_FREQUENCY = pn_visualizer.apply(net, initial_marking, final_marking, parameters=parameters, variant=pn_visualizer.Variants.FREQUENCY, log=refined_event_log)
# display the petri net decorated with the specified variant
pn_visualizer.view(gviz_FREQUENCY)
replaying log with TBR, completed variants :: 0%| | 0/98 [00:00<?, ?it/s]

By decorating the Petri net with frequency information, it is also found that the disputes that happen throughout the process are unexpected and are relatively rare occurances. This can be inferred from the relatively low proportion of frequency between the activity of dispute with supplier purchasing agent and the previous state’s activity (deliver goods services). These disputes disrupt the flow of business processes and add more workload for workers, causing them to be more suspectible to fatigue. Fatigued workers are more likely to cause human errors, which in turn may cause more disputes. Therefore, it is important to prevent disputes as much as possible by analyzing the root causes of disputes.
Raw Data Feature Engineering
The raw data should be engineered further to enchance the capabilities of PM algorithms on analyzing processes.
import numpy as np
# Highlighting the existance of disputes for each instance of a purchasing request
raw_df['dispute existance - event level'] = ['dispute' if 'dispute' in value else 'no dispute' for value in raw_df['Activity'].values]
cases_with_disputes = list(raw_df[raw_df['dispute existance - event level'] == 'dispute'].loc[:, 'Case ID'].values)
cases_with_disputes_dict = dict(zip(cases_with_disputes, ['dispute' for case in cases_with_disputes]))
cases_without_disputes = list(raw_df[raw_df['dispute existance - event level'] == 'no dispute'].loc[:, 'Case ID'].values)
cases_without_disputes_dict = dict(zip(cases_without_disputes, ['no dispute' for case in cases_without_disputes]))
from collections import ChainMap
mapping_dict = ChainMap(cases_with_disputes_dict, cases_without_disputes_dict)
raw_df['dispute existance - case level'] = raw_df['Case ID'].map(mapping_dict)
# Create feature to consider the day when each activity is completed
'''
The .strftime() property of datetime datatype returns full weekday name from the given datetime.
'''
raw_df['Day of week Completed'] = pd.to_datetime(raw_df['Complete Timestamp'],
infer_datetime_format = True).dt.strftime('%A')
display(raw_df.head(5))
| Case ID | Start Timestamp | Complete Timestamp | Activity | Resource | Role | case:concept:name | concept:name | time:timestamp | dispute existance - event level | dispute existance - case level | Day of week Completed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 339 | 2011-02-16 14:31:00+00:00 | 2011-02-16 15:23:00+00:00 | Create Purchase Requisition | Nico Ojenbeer | Requester | 339 | Create Purchase Requisition | 2011-02-16 15:23:00+00:00 | no dispute | no dispute | Wednesday |
| 1 | 339 | 2011-02-17 09:34:00+00:00 | 2011-02-17 09:40:00+00:00 | Analyze Purchase Requisition | Maris Freeman | Requester Manager | 339 | Analyze Purchase Requisition | 2011-02-17 09:40:00+00:00 | no dispute | no dispute | Thursday |
| 2 | 339 | 2011-02-17 21:29:00+00:00 | 2011-02-17 21:52:00+00:00 | Amend Purchase Requisition | Elvira Lores | Requester | 339 | Amend Purchase Requisition | 2011-02-17 21:52:00+00:00 | no dispute | no dispute | Thursday |
| 3 | 339 | 2011-02-18 17:24:00+00:00 | 2011-02-18 17:30:00+00:00 | Analyze Purchase Requisition | Heinz Gutschmidt | Requester Manager | 339 | Analyze Purchase Requisition | 2011-02-18 17:30:00+00:00 | no dispute | no dispute | Friday |
| 4 | 339 | 2011-02-18 17:36:00+00:00 | 2011-02-18 17:38:00+00:00 | Create Request for Quotation Requester Manager | Francis Odell | Requester Manager | 339 | Create Request for Quotation Requester Manager | 2011-02-18 17:38:00+00:00 | no dispute | no dispute | Friday |
# format the new, engineered, raw dataframe with pm4py attributes to ensure accurate interpretation of the dataframe by pm4py modules.
formatted_engineered_df = pm4py.format_dataframe(raw_df, case_id='Case ID', activity_key='Activity', start_timestamp_key='Start Timestamp', timestamp_key = 'Complete Timestamp')
# convert the formatted dataframe into an event log, ensure that the dataframe has been
## formatted with pm4py attributes to ensure accurate interpretation of the dataframe by pm4py modules.
engineered_raw_event_log = pm4py.convert_to_event_log(formatted_engineered_df)
display(engineered_raw_event_log)
[{'attributes': {'concept:name': '1'}, 'events': [{'Case ID': 1, 'Start Timestamp': Timestamp('2011-01-01 00:00:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-01-01 00:37:00+0000', tz='UTC'), 'Activity': 'Create Purchase Requisition', 'Resource': 'Kim Passa', 'Role': 'Requester', 'dispute existance - event level': 'no dispute', 'dispute existance - case level': 'no dispute', 'Day of week Completed': 'Saturday', 'concept:name': 'Create Purchase Requisition', 'time:timestamp': Timestamp('2011-01-01 00:37:00+0000', tz='UTC'), '@@index': 0, 'start_timestamp': Timestamp('2011-01-01 00:00:00+0000', tz='UTC')}, '..', {'Case ID': 1, 'Start Timestamp': Timestamp('2011-01-04 15:22:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-01-04 15:31:00+0000', tz='UTC'), 'Activity': 'Pay invoice', 'Resource': 'Pedro Alvares', 'Role': 'Financial Manager', 'dispute existance - event level': 'no dispute', 'dispute existance - case level': 'no dispute', 'Day of week Completed': 'Tuesday', 'concept:name': 'Pay invoice', 'time:timestamp': Timestamp('2011-01-04 15:31:00+0000', tz='UTC'), '@@index': 16, 'start_timestamp': Timestamp('2011-01-04 15:22:00+0000', tz='UTC')}]}, '....', {'attributes': {'concept:name': '997'}, 'events': [{'Case ID': 997, 'Start Timestamp': Timestamp('2011-05-25 04:20:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-05-25 05:04:00+0000', tz='UTC'), 'Activity': 'Create Purchase Requisition', 'Resource': 'Kim Passa', 'Role': 'Requester', 'dispute existance - event level': 'no dispute', 'dispute existance - case level': 'no dispute', 'Day of week Completed': 'Wednesday', 'concept:name': 'Create Purchase Requisition', 'time:timestamp': Timestamp('2011-05-25 05:04:00+0000', tz='UTC'), '@@index': 9115, 'start_timestamp': Timestamp('2011-05-25 04:20:00+0000', tz='UTC')}, '..', {'Case ID': 997, 'Start Timestamp': Timestamp('2011-05-29 10:18:00+0000', tz='UTC'), 'Complete Timestamp': Timestamp('2011-05-29 10:44:00+0000', tz='UTC'), 'Activity': 'Analyze Request for Quotation', 'Resource': 'Magdalena Predutta', 'Role': 'Purchasing Agent', 'dispute existance - event level': 'no dispute', 'dispute existance - case level': 'no dispute', 'Day of week Completed': 'Sunday', 'concept:name': 'Analyze Request for Quotation', 'time:timestamp': Timestamp('2011-05-29 10:44:00+0000', tz='UTC'), '@@index': 9118, 'start_timestamp': Timestamp('2011-05-29 10:18:00+0000', tz='UTC')}]}]
from pm4py.objects.log.util import interval_lifecycle
from pm4py.util import constants
'''
To store the calculated cycle time and lead time, PM4PY assigns the values to the following attributes =
@@approx_bh_partial_cycle_time: Incremental cycle time associated to the event (the cycle time of the last event is the cycle time of the instance)
@@approx_bh_partial_lead_time: Incremental lead time associated to the event
@@approx_bh_overall_wasted_time: Difference between the partial lead time and the partial cycle time values
@@approx_bh_this_wasted_time: Wasted time ONLY with regards to the activity described by the ‘interval’ event
@@approx_bh_ratio_cycle_lead_time: Measures the incremental Flow Rate (between 0 and 1).
'''
refined_event_log = interval_lifecycle.assign_lead_cycle_time(engineered_raw_event_log, parameters={
constants.PARAMETER_CONSTANT_START_TIMESTAMP_KEY: "start_timestamp",
constants.PARAMETER_CONSTANT_TIMESTAMP_KEY: "time:timestamp"})
Integrating Engineered Features into the event log
After engineering some additional features, they are extracted along with other additional information of the process based on the event log.
# Manual feature selection
import pm4py.algo.transformation.log_to_features.variants.trace_based as log_to_features_trb
'''
str_ev_attr = String attributes at the event level: these are hot-encoded into features that may assume value 0 or value 1.
str_tr_attr = String attributes at the trace level: these are hot-encoded into features that may assume value 0 or value 1.
num_ev_attr = Numeric attributes at the event level: these are encoded by including the last value of the attribute among the events of the trace.
num_tr_attr = Numeric attributes at trace level: these are encoded by including the numerical value.
str_evsucc_attr = Successions related to the string attributes values at the event level: for example, if we have a trace [A,B,C], it might be important to include not only the presence of the single values A, B and C as features; but also the presence of the directly-follows couples (A,B) and (B,C).
'''
# Extracting additional information (exc. cycle time and lead time) about:
## The resource that executes each process for each case
## If a process execution contains, or not, a directly-follows path between different resources.
## The duration of each case.
## The workload of each resource.
feature_parameters = {"str_ev_attr": ["Day of week Completed"],
"str_tr_attr": [],
"num_ev_attr": ["@@approx_bh_partial_cycle_time", "@@approx_bh_partial_lead_time", "@@approx_bh_overall_wasted_time", "@@approx_bh_this_wasted_time", "@approx_bh_ratio_cycle_lead_time"],
"num_tr_attr": [],
"str_evsucc_attr": [],
log_to_features_trb.Parameters.ENABLE_CASE_DURATION: True,
log_to_features_trb.Parameters.RESOURCE_KEY: "Resource",
log_to_features_trb.Parameters.ENABLE_RESOURCE_WORKLOAD: True}
feature_data, feature_names = log_to_features_trb.apply(refined_event_log, parameters=feature_parameters)
print("Each row represents a breakdown of an unique Case ID.")
print(len(feature_names),
np.array(feature_data).shape,
sep = '\n')
Each row represents a breakdown of an unique Case ID.
40
(608, 40)
import pandas as pd
feature_df = pd.DataFrame(data = feature_data, columns = feature_names)
feature_df.head(5)
| event:Day of week Completed@Friday | event:Day of week Completed@Monday | event:Day of week Completed@Saturday | event:Day of week Completed@Sunday | event:Day of week Completed@Thursday | event:Day of week Completed@Tuesday | event:Day of week Completed@Wednesday | event:@@approx_bh_partial_cycle_time | event:@@approx_bh_partial_lead_time | event:@@approx_bh_overall_wasted_time | ... | resource_workload@@Kim Passa | resource_workload@@Kiu Kan | resource_workload@@Magdalena Predutta | resource_workload@@Maris Freeman | resource_workload@@Miu Hanwan | resource_workload@@Nico Ojenbeer | resource_workload@@Pedro Alvares | resource_workload@@Penn Osterwalder | resource_workload@@Sean Manney | resource_workload@@Tesca Lobes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 900.0 | 96720.0 | 95820.0 | ... | 6 | 15 | 28 | 0 | 0 | 0 | 22 | 0 | 12 | 12 |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 43440.0 | 261120.0 | 217680.0 | ... | 0 | 36 | 0 | 0 | 0 | 26 | 61 | 0 | 0 | 27 |
| 2 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 2220.0 | 38220.0 | 36000.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 600.0 | 121860.0 | 121260.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 18 |
| 4 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0.0 | 324000.0 | 324000.0 | ... | 0 | 0 | 62 | 0 | 28 | 0 | 0 | 0 | 0 | 0 |
5 rows × 40 columns
Root Cause Analysis (unfit activities)
To analyze the symptoms and reasons why disputes happen, the decision tree algorithm can be used. Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning simple decision rules (a.k.a. symptoms) inferred from the data features. In this case, the target variable is the existance of disputes.
In concept, decision trees are similar with graphs. Both have nodes and arcs. Nodes in decision trees are called leaves (leaf in singular) and arcs are called branches. Each internal or source leaf node represents a “test” on an attribute (e.g. whether a coin flip comes up heads or tails) and each destination leaf node represents a class label (decision taken after computing all attributes) while each branch represents the outcome of the test.
As a general rule, one should look for leaf nodes with the lowest Gini impurity score and the largest sample size of the target class. These leaf nodes can be reliably referred to as decision rules which might contain information about the symptoms of the problem. Therefore, these leaf nodes should be studied further so the solution for the problem and its symptoms can be identified. The estimation on whether the solution will work or not should be done using Discrete Event Simulation (DES) with the base model constructed from the model of real processes that has been discovered by process mining.
from pm4py.objects.log.util.get_class_representation import get_class_representation_by_str_ev_attr_value_presence
'''
dispute == True
'''
target, classes = get_class_representation_by_str_ev_attr_value_presence(refined_event_log, str_attr_name = 'dispute existance - case level', str_attr_value = 'dispute')
print(len(classes),
np.array(target).shape,
sep = '\n')
2
(608,)
from sklearn import tree
'''
max_depth=7 is the default value for the max_depth parameter in most of PM4PY's sklearn decision tree implementation.
random_state=0 to ensure reproducibility of the model.
'''
act_clf = tree.DecisionTreeClassifier(max_depth=7,
random_state=0)
act_clf.fit(feature_df, target)
from pm4py.visualization.decisiontree import visualizer as dectree_visualizer
gviz = dectree_visualizer.apply(act_clf, feature_names, classes)
dectree_visualizer.view(gviz)
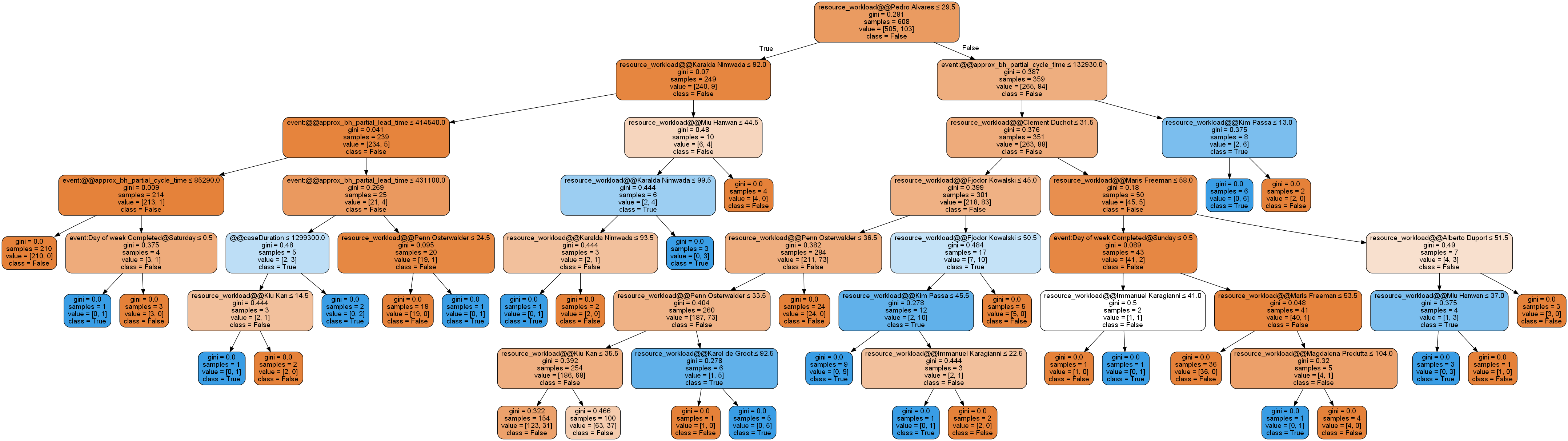
Reference
- Zerbino, P., Stefanini, A., & Aloini, D. (2021). Process Science in Action: A Literature Review on Process Mining in Business Management. Technological Forecasting and Social Change, 172, 121021. doi:10.1016/j.techfore.2021.121021
- Wil, A. (2018, July 9–12). PROCESS MINING AND SIMULATION: A MATCH MADE IN HEAVEN! [Keynote paper]. SpringSim-SCSC, Bordeaux, France. DOI:10.22360/summersim.2018.scsc.005
- Milani, F., Fredrik & Lashkevich, Katsiaryna & Maggi, Fabrizio & Di Francescomarino, Chiara. (2022). Process Mining: A Guide for Practitioners. 10.1007/978-3-031-05760-1_16.
- van Eck, M.L., Lu, X., Leemans, S.J.J., van der Aalst, W.M.P. (2015). PM2: A Process Mining Project Methodology. In: Zdravkovic, J., Kirikova, M., Johannesson, P. (eds) Advanced Information Systems Engineering. CAiSE 2015. Lecture Notes in Computer Science, vol 9097. Springer, Cham. doi:10.1007/978-3-319-19069-3_19